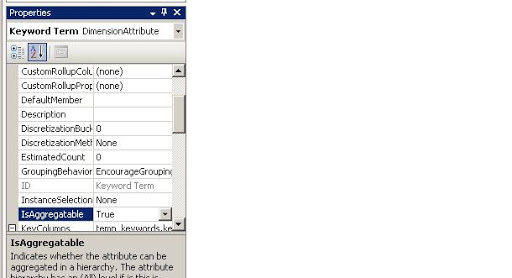
As we all know that DistinctCount is a challenge for SSAS. Since its not an additive measure
AS needs additional efforts to get distinct count.
There are number of articles on how to optimize distinct count.
In general there we can get distinct count by two ways
1. Set aggregation usage of Distinctcount type while designing cube.
2. Using DistinctCount MDX Function
There are some alternate ways also available on how to count distinctcount
Lets look at another approach on how to get distinctcount.
Our problem is to get distinctcount of product sold by each reseller.
first we will get products for which orders are placed
nonempty([Product].[Product].members,[Measures].[Reseller Order Count])
Then we will count this number of products
count( nonempty([Product].[Product].members,[Measures].[Reseller Order Count]))
member [measures].[dc1]
Here it is count of individual products for which orders are placed and that is distinctcount for us also
WITH MEMBER [measures].[AlternateDistinctCount]
AS
COUNT( nonempty([Product].[Product].MEMBERS,[Measures].[Reseller Order Count]))
MEMBER [measures].[MDXDistinctCount]
AS
DISTINCTCOUNT({[Product].[Product].members*[Measures].[Reseller Order Count]})
SELECT {[measures].[AlternateDistinctCount],[measures].[MDXDistinctCount]} ON 0,
[Reseller].[Reseller].MEMBERS
ON 1
FROM [Adventure Works]
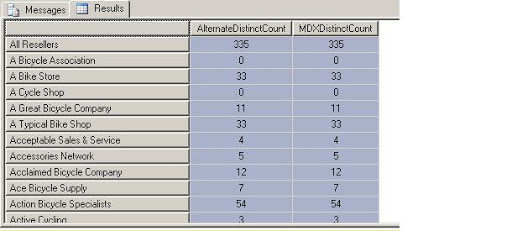
Lets verify the result
A Bike Store 33 33
A Bike Store has placed orders for 33 products
SELECT
[Reseller].[Reseller].&[1] ON 0,
NON EMPTY{[Product].[Product].MEMBERS*[Measures].[Reseller Order Count]} ON 1
FROM
[Adventure Works]
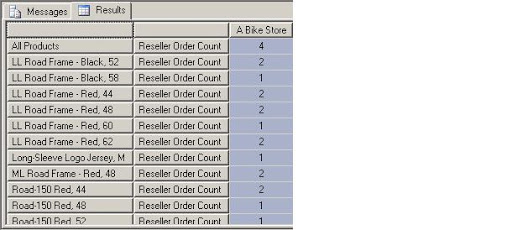
It shows orders placed for 33 products